Guatemala vuelve a aparecer en una publicación de actor de amenazas.
Esta vez, el actor afirma haber comprometido sistemas del Ministerio de Educación y haber obtenido una cantidad masiva de documentos PDF con información sensible.
MINEDUC, hasta donde he observado, no ha confirmado públicamente el incidente ni el alcance total alegado por el actor.
Dicho eso, en este caso la evidencia no se queda solo en una captura, un texto de foro o una afirmación difícil de validar.
Revisé una PoC publicada por el actor y el contenido observado sí contiene documentos sensibles.
La muestra incluye miles de PDFs. En los archivos revisados se observaron documentos con datos personales, DPI, solicitudes, títulos, cédulas docentes y otros documentos multipágina vinculados al ámbito educativo.
El actor afirma que el volumen total asciende a 178 GB y 150 mil PDFs. Ese alcance total debe ser validado por la institución correspondiente. Lo que sí puede afirmarse con base en la PoC revisada es que la muestra contiene volumen, variedad documental y datos sensibles suficientes para tratar el caso como una exposición seria de información.

Nota de divulgación responsable
Este análisis no publica URLs completas, tokens, documentos descargables, credenciales ni datos personales.
Las capturas que se utilicen como evidencia deben estar censuradas para evitar exponer DPI, nombres, fotografías, documentos completos, enlaces de descarga, rutas completas o parámetros reutilizables.
El objetivo de esta publicación es documentar hallazgos técnicos de forma responsable, no facilitar abuso adicional.
Resumen ejecutivo
La evidencia revisada apunta a una exposición seria de documentos sensibles asociados al Ministerio de Educación.
El elemento técnico más importante de la PoC no es únicamente la existencia de PDFs. Es el archivo descarga.log, que permite reconstruir parcialmente un proceso automatizado de descarga.
El log muestra intentos secuenciales contra documentos PDF, respuestas exitosas, respuestas 404 Not Found, errores aislados, una ventana temporal clara y ausencia de saltos en el rango de IDs.
Esto no parece una recolección manual de archivos aislados. La evidencia apunta a enumeración y descarga automatizada.
La pregunta principal no debería ser solo quién publicó la información.
La pregunta más urgente es:
¿Por qué fue posible descargar tantos documentos de forma automatizada?
Evidencia observada en la PoC
La PoC descargada contiene miles de archivos PDF con nombres numéricos, por ejemplo:
00001000.pdf
00001001.pdf
00001016.pdf
00001017.pdf
Este patrón de nombres ya sugiere una relación con identificadores o secuencias internas.
Los documentos observados incluyen archivos multipágina y contenido sensible vinculado al ámbito educativo, como:
- DPI
- solicitudes
- títulos
- cédulas docentes
- documentos administrativos
- información personal asociada a trámites educativos
No se reproducen documentos ni datos personales en esta publicación.

Hallazgo principal: el archivo descarga.log
La PoC incluye un archivo descarga.log, que es probablemente la evidencia técnica más importante del caso.
Se preservó el hash del archivo para referencia:
SHA256 descarga.log:
4d88ed64997b0b01098070f3bcbf24c368f613978c3ea41c2fa03b0fbc2285b0
El archivo tenía un tamaño de 237,450 bytes.
El análisis del log permitió identificar los siguientes datos:
| Métrica | Valor observado |
|---|---|
| Primer timestamp | 2026-04-30 01:38:15,793 |
| Último timestamp | 2026-04-30 02:20:56,542 |
| Duración aproximada | 42 minutos 40 segundos |
| Intentos totales | 2,631 |
| ID mínimo | 1000 |
| ID máximo | 3630 |
| Rango teórico de IDs | 2,631 |
| Gaps detectados | 0 |
| PDFs descargados correctamente | 2,005 |
| Respuestas 404 | 624 |
| Errores | 2 |
| Bytes descargados correctamente | 2,734,378,236 |
| Tamaño aproximado descargado | 2.55 GB |
| Total de páginas | 13,817 |
| Promedio de páginas por PDF | 6.89 |
El punto más importante es este:
El rango va del ID 1000 al 3630, con 2,631 intentos y cero gaps.
Eso apunta a una enumeración secuencial automatizada.
La PoC revisada muestra ese rango específico, pero el método observado es más delicado: el log evidencia que el proceso consistió en recorrer IDs secuenciales y descargar los documentos que existían.
En otras palabras, el riesgo no está limitado a los 2,631 intentos observados en la PoC. Ese rango es una muestra del mecanismo utilizado. Para ampliar la extracción, bastaría ejecutar el mismo patrón sobre otros rangos de IDs, siempre que el sistema no valide correctamente cada documento del lado del servidor.
No puedo afirmar desde la PoC que el actor descargó la totalidad de los 178 GB alegados, porque ese alcance debe validarse. Pero el log sí demuestra el método de extracción: enumeración secuencial y descarga automatizada de documentos disponibles.
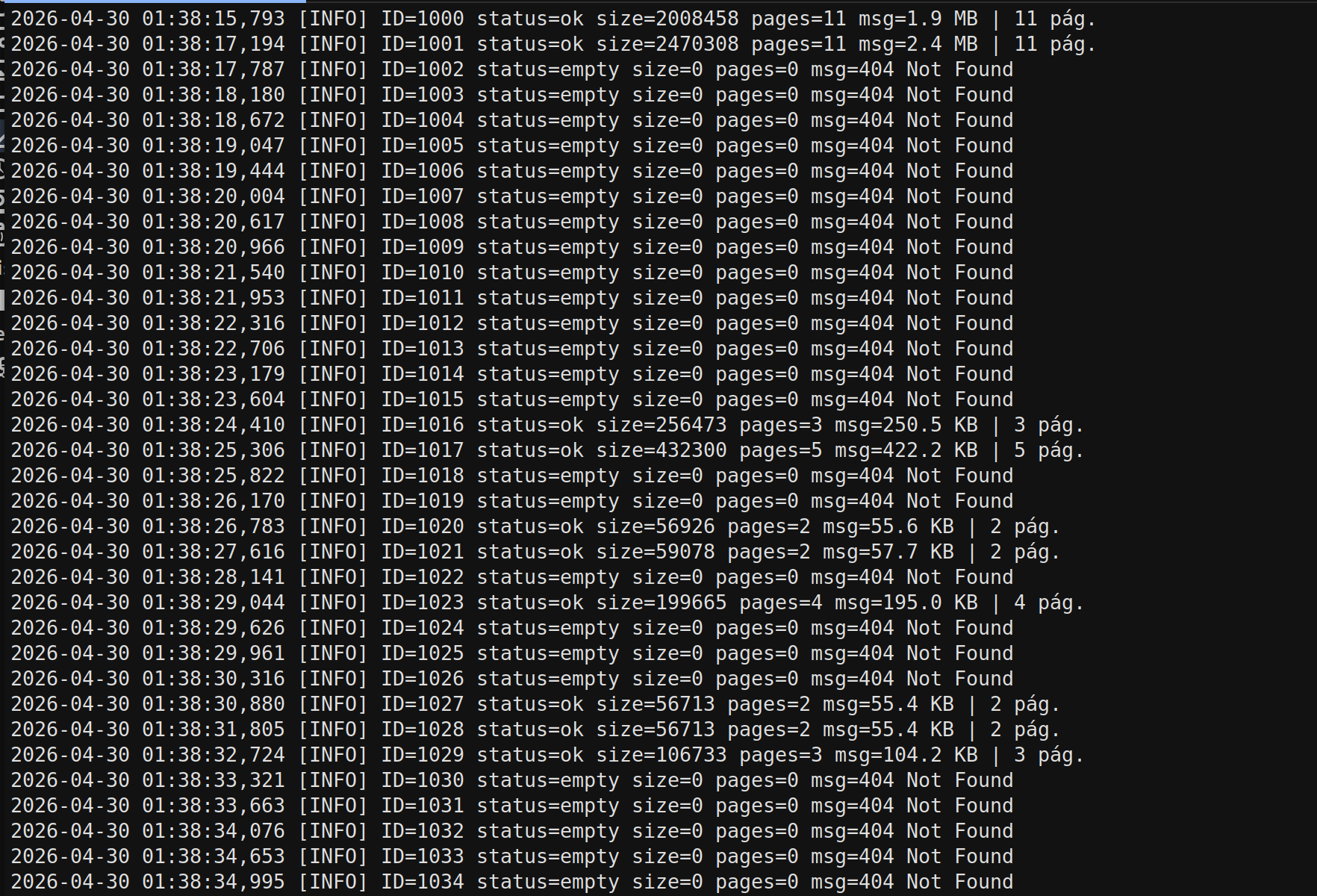
Patrón de descarga observado
En la evidencia revisada se observó un descarga.log con múltiples intentos secuenciales de descarga contra rutas de documentos PDF en el dominio bpm.mineduc.gob.gt.
El log muestra solicitudes automatizadas hacia una ruta de almacenamiento documental, con respuestas ok, 404 Not Found y algunos errores aislados. Esto apunta a un patrón de enumeración y descarga automatizada de documentos expuestos, más que a una filtración manual aislada.
No se publican rutas completas, tokens, parámetros ni nombres de archivos específicos, porque podrían facilitar abuso adicional.
Sin embargo, la lectura técnica es relevante: si un documento sensible puede recuperarse mediante una URL directa y el control de acceso depende principalmente de la estructura del enlace o de un parámetro reutilizable, el riesgo de extracción masiva aumenta considerablemente.
Además, por la velocidad observada en el log, no parece haber existido un rate limiting efectivo o un control capaz de detener la descarga repetitiva de documentos. La evidencia también sugiere que el parámetro usado en la URL no actuaba como una validación fuerte de acceso, o al menos no impidió la descarga automatizada dentro del rango observado.
Por qué los 404 importan
Los 404 Not Found no debilitan el hallazgo. Al contrario, ayudan a entender el método.
Si un script recorre identificadores del 1000 al 3630, es normal que algunos documentos existan y otros no.
Por eso aparecen:
status=okcuando el PDF existe y se descargastatus=emptyo404 Not Foundcuando el ID no tiene documento asociado- errores aislados en la ejecución
Ese comportamiento es consistente con enumeración.
No es el patrón esperado de una navegación humana normal.
Velocidad y automatización
El log también permite observar actividad por minuto.
Durante varios minutos se observan decenas de descargas exitosas por minuto. En algunos cortes se observan más de 50 o 60 descargas exitosas en un minuto.
Una persona no descarga, abre, valida y guarda manualmente miles de PDFs multipágina en una ventana de 42 minutos.
Un script sí.
Esto refuerza la lectura de automatización.
Qué sugiere técnicamente
La evidencia apunta a que el actor pudo automatizar la recuperación de documentos PDF desde una ruta documental expuesta o débilmente protegida.
El problema no sería únicamente que existían PDFs.
El problema sería que la forma de acceso a esos PDFs pudo ser automatizable.
Si un sistema permite recuperar documentos sensibles mediante:
- rutas directas a archivos
- identificadores secuenciales
- nombres predecibles
- parámetros tipo token usados solo como referencia
- enlaces sin validación fuerte del lado del servidor
- ausencia de autorización por documento
- falta de rate limiting
- ausencia de alertas por descarga masiva
entonces el riesgo no es una exposición puntual.
La observación clave es que no basta con que la URL tenga un valor largo o aparentemente aleatorio. Si el servidor entrega el PDF sin verificar que el usuario está autenticado y autorizado para acceder a ese documento específico, el token deja de ser un control de seguridad real y se convierte únicamente en parte de la ruta.
El riesgo es extracción masiva.
Y eso es exactamente lo que el log parece mostrar.
Impacto potencial
Los documentos observados no son datos triviales.
Cuando se exponen documentos con DPI, información académica, títulos, solicitudes, fotografías, datos administrativos o constancias, el impacto puede mantenerse durante años.
Una contraseña se puede cambiar.
Un token se puede revocar.
Un documento personal filtrado no se recupera de la misma forma.
Este tipo de información puede ser utilizada para:
- suplantación de identidad
- fraude documental
- ingeniería social dirigida
- extorsión
- creación de perfiles de ciudadanos
- abuso de información de docentes o personal educativo
- reutilización de documentos en otros fraudes
- validación fraudulenta de trámites
- ataques dirigidos contra personas vinculadas al sistema educativo
El riesgo no termina cuando se baja un enlace o se cierra un acceso. Si los documentos ya fueron descargados, el impacto debe gestionarse como exposición de datos, no solo como incidente técnico.
Qué debería investigarse
Más allá de la atribución del actor, hay preguntas técnicas urgentes:
- Qué sistema generaba o almacenaba esos PDFs.
- Si los documentos eran accesibles sin autenticación.
- Si existía autorización por usuario y por documento.
- Si los identificadores eran secuenciales o predecibles.
- Si las URLs tenían tokens reales de acceso o solo parámetros de referencia.
- Si los enlaces expiraban o eran permanentes.
- Si hubo rate limiting o alertas por descarga masiva.
- Si los logs del servidor confirman la misma ventana de extracción.
- Si hubo accesos similares antes o después del periodo observado.
- Si el patrón afecta otros módulos documentales.
- Si los documentos fueron accedidos desde una sola IP, varias IPs o infraestructura distribuida.
- Si existían controles de monitoreo capaces de detectar más de 2,000 descargas en menos de una hora.
La pregunta principal no debería ser solo “quién lo hizo”.
La pregunta más importante es:
¿Por qué fue posible descargar tantos documentos de forma automatizada?
Recomendaciones inmediatas
Para una entidad afectada por un caso de este tipo, las acciones iniciales deberían enfocarse en contención y validación técnica.
- Deshabilitar acceso público directo a documentos sensibles.
- Invalidar enlaces generados previamente si no cuentan con autorización robusta.
- Revisar si los documentos pueden descargarse sin sesión autenticada.
- Validar que cada descarga aplique autorización del lado del servidor.
- Revisar si los IDs, rutas o nombres de archivos son secuenciales o enumerables.
- Implementar rate limiting por IP, sesión, usuario y patrón de recurso.
- Revisar logs por IP origen, User-Agent, frecuencia, volumen transferido y rangos de documentos solicitados.
- Buscar actividad histórica similar, no solo la ventana reportada en la PoC.
- Rotar credenciales administrativas relacionadas con el sistema documental.
- Revisar cuentas de servicio, integraciones y permisos de almacenamiento.
- Identificar exactamente qué documentos fueron accedidos.
- Preparar un proceso formal de notificación si se confirma exposición de datos personales.
Controles técnicos que deberían validarse
El patrón observado no se corrige únicamente “ocultando” la ruta del archivo. Si el documento puede descargarse directamente desde una URL y el servidor no valida sesión, autorización y contexto de acceso, el problema sigue existiendo.
Estos controles deberían revisarse específicamente:
1. Autorización fuerte por documento
Cada descarga debe validar del lado del servidor:
- usuario autenticado
- sesión válida
- permiso explícito sobre ese documento
- relación entre usuario, trámite, expediente o rol
- estado del documento
- vigencia del acceso
No debería ser posible descargar un PDF solo por conocer o modificar un identificador.
2. Evitar identificadores secuenciales expuestos
El log muestra recorrido secuencial de IDs. Eso es una señal clara de enumeración.
Los sistemas no deberían exponer IDs incrementales o predecibles para documentos sensibles. Si internamente existen IDs secuenciales, no deberían ser usados directamente en URLs públicas o descargables.
Usar UUIDs o identificadores no predecibles ayuda, pero no sustituye la autorización. Un UUID sin control de acceso sigue siendo un enlace expuesto.
3. Tokens firmados y con expiración real
Si se usan enlaces temporales, el token debe ser:
- firmado del lado del servidor
- no reutilizable indefinidamente
- asociado al usuario o sesión
- asociado al documento específico
- con expiración corta
- invalidable
- no válido desde otra sesión o contexto
Un parámetro largo en la URL no es seguridad si el servidor no valida quién lo está usando y para qué documento.
4. Sesiones fuertes
Las descargas de documentos sensibles deberían requerir sesión activa y controles de sesión robustos:
- cookies
HttpOnly - cookies
Secure SameSiteadecuado- expiración por inactividad
- renovación controlada de sesión
- invalidación al cerrar sesión
- protección contra reutilización de enlaces fuera de sesión
- validación de CSRF donde aplique
- MFA para usuarios administrativos o perfiles con acceso masivo
Un enlace copiado no debería funcionar desde otro navegador, otro usuario o una sesión no autorizada.
5. Control contra descarga masiva
El log muestra miles de intentos en una ventana aproximada de 42 minutos. Eso debería activar controles automáticos.
Se deberían implementar límites por:
- IP
- usuario
- sesión
- documento
- rango de IDs
- cantidad de descargas por minuto
- volumen transferido
- cantidad de respuestas 404
- patrón de navegación no humano
No se trata solo de bloquear “muchas peticiones”. Un patrón de 404 repetidos sobre IDs consecutivos debería ser una señal fuerte de enumeración.
6. CAPTCHA o desafío adaptativo
CAPTCHA no debe ser el control principal para proteger documentos sensibles, pero puede servir como control adicional cuando se detecta comportamiento anómalo.
Por ejemplo:
- muchas descargas en poco tiempo
- muchos 404 consecutivos
- navegación por IDs secuenciales
- cambio brusco de volumen descargado
- comportamiento sin interacción normal de usuario
- acceso desde IP o ASN inusual
El CAPTCHA debe ser adaptativo. No debería reemplazar autorización por documento, sesión fuerte ni rate limiting.
7. Respuestas 404 y manejo de errores
Los errores también filtran información.
Si un sistema responde diferente cuando un documento existe y cuando no existe, puede facilitar enumeración. Debe revisarse si las respuestas permiten inferir existencia de documentos.
También conviene monitorear:
- exceso de 404
- secuencias de 404 y 200 alternadas
- solicitudes a documentos inexistentes
- cambios sistemáticos de ID
- intentos desde la misma IP o sesión
8. Almacenamiento no público
Los documentos sensibles no deberían vivir en rutas públicas directamente servidas por el servidor web si no existe una capa de autorización antes.
Una arquitectura más segura sería:
- storage privado
- aplicación como intermediario
- validación de permisos antes de entregar el archivo
- generación de URL temporal solo después de autorizar
- expiración corta
- registro de acceso por usuario y documento
9. Logs útiles para investigación
El sistema debería poder responder rápidamente:
- qué documentos fueron descargados
- por quién
- desde qué IP
- desde qué sesión
- con qué User-Agent
- en qué horario
- cuántas veces
- desde qué país o ASN
- si hubo comportamiento automatizado
- si se intentaron rangos secuenciales
Sin esa trazabilidad, la institución queda limitada a reaccionar por lo que publicó el actor, no por su propia evidencia.
10. Detección específica de enumeración
Se deberían crear alertas para patrones como:
- IDs consecutivos solicitados
- muchos documentos distintos en poco tiempo
- alto volumen de PDFs descargados
- alto número de 404
- descargas fuera de horario normal
- descargas sin navegación previa
- uso repetitivo del mismo endpoint
- ausencia de recursos estáticos típicos de navegación humana
- tasas constantes de solicitud
El patrón observado en el descarga.log debió ser detectable.
Recomendaciones de fondo
Este caso no debería tratarse únicamente como “bajar un sitio” o “cerrar un enlace”.
El problema de fondo suele estar en la arquitectura de acceso a documentos.
Un sistema documental que maneja información sensible debería tener, como mínimo:
- autenticación obligatoria
- autorización por documento
- enlaces temporales con expiración real
- validación del lado del servidor
- registros de acceso por usuario y documento
- alertas por descarga masiva
- separación entre documentos públicos y privados
- control de exposición de storage
- pruebas de abuso de lógica de negocio
- revisión periódica de permisos
- inventario de documentos sensibles
- monitoreo de rutas de almacenamiento
La seguridad no puede depender de que una URL sea “difícil de adivinar”.
Y mucho menos cuando hay datos personales o documentos institucionales de por medio.
Otros eventos observados
Además del caso de MINEDUC, se observaron publicaciones asociadas al alias NemorisHacking en las que se mencionan otros objetivos en Guatemala.
La evidencia observada no debe tratarse toda con el mismo nivel de certeza. Hay que separar defacement, exposición de credenciales, acceso aparente, intento de acceso, evidencia antigua reutilizada y compromiso confirmado.
POS Virtual
Se observó un defacement en una ruta de link.posvirtual.gt.
Este caso requiere una lectura cuidadosa. La evidencia visible permite afirmar defacement de una ruta específica, pero no permite concluir, por sí sola, que toda la plataforma POS Virtual haya sido comprometida.
El HTML revisado muestra que la página conservaba la estructura normal de POS Virtual, incluyendo formulario, estilos, scripts internos y assets de la plataforma. Sin embargo, el contenido visible, la metadata social, el título y la imagen asociada al link fueron alterados.
Un detalle relevante es la presencia de Tatmon en la landing afectada. El logo se carga desde una ruta asociada a adm.posvirtual.gt/uploads/enterprise/, lo que sugiere que podría tratarse del comercio, cuenta o entidad asociada a ese link de pago.
Esto cambia la lectura del incidente.
El punto no necesariamente sería “compromiso total de POS Virtual”, sino modificación de una landing específica, abuso de una cuenta de comercio, credenciales comprometidas del panel, acceso a un módulo administrativo o alteración de contenido almacenado asociado al link.
También llama la atención que la imagen usada por el actor se servía desde una ruta de uploads asociada a adm.posvirtual.gt/uploads/link/. Eso sugiere que el contenido fue cargado o referenciado desde la propia infraestructura de administración de la plataforma, no simplemente como un recurso externo pegado encima de la página.
La hipótesis más razonable a validar es si el acceso se obtuvo a través de la cuenta o entorno asociado a Tatmon, o mediante credenciales con permisos para editar esa landing.
Para validar este caso habría que revisar:
- comercio o cuenta asociada al link afectado
- historial de cambios del link
- uploads recientes en
adm.posvirtual.gt/uploads/link/ - usuario que subió la imagen del actor
- logs de autenticación del panel
- IP, User-Agent y horario de modificación
- permisos de la cuenta asociada a Tatmon
- si otras landings del mismo comercio fueron modificadas
- si el formulario seguía operativo durante el defacement
- integridad de scripts internos como
buttonPay.js,buttonDownload.js,nit.jsyactions.js
Aunque el defacement es lo visible, la página conservaba elementos funcionales del formulario de pago. Eso hace necesario validar si la ruta siguió operativa durante la ventana del incidente, si recibió datos y si los scripts internos fueron modificados o si solo fue alterado el contenido administrable de la landing.
En resumen: el caso POS Virtual parece más cercano a una modificación de contenido asociado a un comercio o link específico, posiblemente vinculado a Tatmon, que a una evidencia directa de compromiso completo de toda la plataforma.
SIT y PGN
Se observaron publicaciones donde el actor muestra accesos aparentes a portales de SIT y PGN, junto con credenciales asociadas.
No se reproducen usuarios, contraseñas ni URLs completas en esta publicación.
Este tipo de evidencia no permite concluir automáticamente que hubo explotación directa de una vulnerabilidad en la infraestructura. Una posibilidad razonable es el uso de credenciales obtenidas por infostealers, reutilización de contraseñas, credenciales filtradas previamente o cuentas con controles débiles.
En el caso de SIT, esta hipótesis toma más fuerza porque la institución publicó un comunicado indicando que, con base en su análisis forense preliminar, la exposición de credenciales se habría originado en dispositivos comprometidos mediante software malicioso, y no en una intrusión directa a la infraestructura institucional.
Aun así, si las credenciales estaban vigentes, el impacto puede ser real. El riesgo depende del perfil de la cuenta, los permisos asignados, la vigencia de la sesión, la existencia de MFA y las acciones realizadas dentro del sistema.

Lectura
El patrón común no es solo el ruido del actor. Es la exposición pública de evidencia operativa: defacements, credenciales y accesos aparentes a portales.
No todo tiene el mismo peso probatorio.
Una credencial publicada no prueba por sí sola extracción masiva. Un acceso con usuario válido tampoco necesariamente implica que el servidor haya sido vulnerado.
Pero todas son señales que deben revisarse.
Las acciones mínimas deberían ser:
- validar si las credenciales publicadas siguen vigentes
- forzar rotación de contraseñas
- invalidar sesiones activas
- revisar accesos recientes de las cuentas afectadas
- confirmar si existe MFA
- buscar inicios de sesión desde IPs, países, ASN o dispositivos inusuales
- revisar User-Agent y horarios de acceso
- verificar si hubo cambios o descargas dentro de los portales
- preservar logs antes de que roten
- revisar exposición previa en stealer logs o filtraciones históricas
En estos casos, la hipótesis de infostealer o credenciales reutilizadas debe considerarse seriamente.
Conclusión
En el caso de MINEDUC, la PoC revisada contiene evidencia suficiente para considerar el incidente como serio.
MINEDUC no ha confirmado públicamente, hasta donde he observado, el incidente ni el alcance total alegado por el actor.
El alcance total anunciado por el actor debe ser confirmado por la institución correspondiente. Pero la muestra observada ya amerita investigación, contención y comunicación responsable.
La muestra revisada contiene documentos sensibles y un log técnico que apunta a descarga automatizada.
El foco no debería quedarse en el actor ni en el ruido del foro.
El foco debería estar en responder:
- qué información fue accesible
- por cuánto tiempo estuvo expuesta
- qué controles fallaron
- qué personas podrían verse afectadas
- cómo se evita que vuelva a ocurrir
Guatemala necesita dejar de tratar estos eventos como casos aislados.
Cuando se repiten filtraciones, defacements, APIs expuestas, credenciales viejas reutilizadas y documentos descargables, el patrón ya no es ruido.
Es una señal de baja madurez en protección de información pública sensible.
Y eso no se corrige con comunicados.
Se corrige con inventario, control de acceso, monitoreo real, trazabilidad, respuesta técnica y responsabilidad institucional.